Natural Language Processing
Contents
Natural Language Processing¶
Learning goals:¶
Familiarize with the natural language analysis toolkit NLTK (Natural Language Toolkit)
Do more advanced corpus analyses
NLTK-library¶
The NLTK-library is a library containing language analysis tools, developed to simplify the process of doing more advanced language analysis on the computer. Most of the functions that can be found in this library will not be used in this course, but may be useful at a later point in the educational process. For the interested reader the features of this library are described to a wide extent in the NLTK book, which can be found through the following link, http://www.nltk.org/book/. Chapter 2 of the book deals with corpus analysis, which is one of the main topics of this course.
Importing texts from the NLTK-library¶
Up until now we have used texts either given in separate .txt-files or found on the Internet for our discussion. The NLTK-library does, however, also contain a series of text corpora which are useful for general text analysis.
For example, a small section of the texts in the Project Gutenberg text collection is saved in the “gutenberg” corpus in NLTK. To use the tools of the NLTK-library and access the corpora that it contains one must install NLTK on the computer. How to do this is shown in the following link, http://www.nltk.org/install.html.
After installing NLTK it must be imported in the program that will make use of it. The following line imports all the features of the NLTK-library.
import nltk
If only a section of the features from the NLTK-library is needed, it is possible to import this section only. In the example below the gutenberg corpus is imported from the NLTK-library, and the texts it contains are printed to screen.
from nltk.corpus import gutenberg
textfiles = gutenberg.fileids()
print(textfiles)
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Note that the gutenberg corpus lies in the corpus section of NLTK. Thus we must write nltk.corpus to access the corpora of NLTK.
Words¶
Splitting a text file into tokens of words can easily be done by utilizing the string manipulation tool split introduced in the first week of lectures on computational linguistics. For most purposes of this course, where we mostly do qualitative language analysis, dividing a text into words in this way is sufficient. Nevertheless we have seen in the exercises that the split-function does not know how to handle contracted words such as “I’m”, “we’re” etc., and we need to manually remove characters such as “!”, “.” and “,” from the words.
The NLTK library contains functions that make the process of dividing a text into tokens of words both easier and more correct.
Texts on the computer¶
The next example shows how a text can be structured into a list of words and signs using the word-function in the NLTK-library. This function is part of the corpus section and is activated in the following way,
from nltk.corpus import gutenberg
hamlet = gutenberg.words("shakespeare-hamlet.txt")
list_of_tokens = hamlet[:70]
print(list_of_tokens)
['[', 'The', 'Tragedie', 'of', 'Hamlet', 'by', 'William', 'Shakespeare', '1599', ']', 'Actus', 'Primus', '.', 'Scoena', 'Prima', '.', 'Enter', 'Barnardo', 'and', 'Francisco', 'two', 'Centinels', '.', 'Barnardo', '.', 'Who', "'", 's', 'there', '?', 'Fran', '.', 'Nay', 'answer', 'me', ':', 'Stand', '&', 'vnfold', 'your', 'selfe', 'Bar', '.', 'Long', 'liue', 'the', 'King', 'Fran', '.', 'Barnardo', '?', 'Bar', '.', 'He', 'Fran', '.', 'You', 'come', 'most', 'carefully', 'vpon', 'your', 'houre', 'Bar', '.', "'", 'Tis', 'now', 'strook', 'twelue']
In the example above we see that for example “Who’s” is split into “Who”, “’” and “s”. This does of course not solve the problem of splitting “Who’s” into “Who” and “is”, but it does recognise that it is a composition of two words. We also see that all sign characters are regarded as distinct words, and separated from the letters of the text.
Often we will only be interested in the tokens of words that occur in a text, and not all the numbers and punctuations that come with it. The built-in Python function isalpha constitutes such a functionality. How this function is implemented is shown in the example below.
word_tokens = list(word for word in list_of_tokens if word.isalpha())
print(word_tokens)
['The', 'Tragedie', 'of', 'Hamlet', 'by', 'William', 'Shakespeare', 'Actus', 'Primus', 'Scoena', 'Prima', 'Enter', 'Barnardo', 'and', 'Francisco', 'two', 'Centinels', 'Barnardo', 'Who', 's', 'there', 'Fran', 'Nay', 'answer', 'me', 'Stand', 'vnfold', 'your', 'selfe', 'Bar', 'Long', 'liue', 'the', 'King', 'Fran', 'Barnardo', 'Bar', 'He', 'Fran', 'You', 'come', 'most', 'carefully', 'vpon', 'your', 'houre', 'Bar', 'Tis', 'now', 'strook', 'twelue']
The built-in Python function set sorts this list into a set of all unique words occuring in the text. A set is a list where all equal objects are collapsed into one object. We use the function lower to make sure that capitalized words are not counted as different from the uncapitalized version. The function list is further used to convert this set to a list again.
unique_words = list(set(word.lower() for word in word_tokens))
print(unique_words)
['by', 'liue', 'come', 'long', 'actus', 'and', 'tragedie', 'the', 'centinels', 'two', 'answer', 'scoena', 'william', 'most', 'houre', 'carefully', 'enter', 'me', 'tis', 'shakespeare', 'selfe', 'primus', 'twelue', 'vpon', 'bar', 'hamlet', 'nay', 'francisco', 'there', 'you', 'king', 's', 'he', 'prima', 'fran', 'barnardo', 'strook', 'your', 'stand', 'who', 'now', 'of', 'vnfold']
To make the difference between these three lists more explicit, we can print their lengths to screen, as shown below.
print(f"The list of tokens consists of {len(list_of_tokens)} words, the list of word tokens consists of {len(word_tokens)} words, and the number of unique words is {len(unique_words)}.")
The list of tokens consists of 70 words, the list of word tokens consists of 51 words, and the number of unique words is 43.
Texts from the web¶
The NLTK-library contains the function word_tokenize() which serves to structure a text file read from the web into tokens. In the example below the text “The Odyssey of Homer” by Homer is imported from the online text resource Project Gutenberg, and the text is structured into a list of words and signs.
from urllib import request
import nltk
url = "https://www.gutenberg.org/files/24269/24269-0.txt"
webpage = request.urlopen(url)
raw = webpage.read().decode("utf8")
tokens = nltk.word_tokenize(raw)
print(type(tokens))
print(tokens[3000:3200])
<class 'list'>
['before', '.', 'For', 'I', 'should', 'less', 'lament', 'even', 'his', 'death', ',', 'Had', 'he', 'among', 'his', 'friends', 'at', 'Ilium', 'fall', "'", 'n', ',', 'Or', 'in', 'the', 'arms', 'of', 'his', 'companions', 'died', ',', 'Troy', "'s", 'siege', 'accomplish', "'d", '.', 'Then', 'his', 'tomb', 'the', 'Greeks', '300', 'Of', "ev'ry", 'tribe', 'had', 'built', ',', 'and', 'for', 'his', 'son', ',', 'He', 'had', 'immortal', 'glory', 'atchieved', ';', 'but', 'now', ',', 'By', 'harpies', 'torn', 'inglorious', ',', 'beyond', 'reach', 'Of', 'eye', 'or', 'ear', 'he', 'lies', ';', 'and', 'hath', 'to', 'me', 'Grief', 'only', ',', 'and', 'unceasing', 'sighs', 'bequeath', "'d", '.', 'Nor', 'mourn', 'I', 'for', 'his', 'sake', 'alone', ';', 'the', 'Gods', 'Have', 'plann', "'d", 'for', 'me', 'still', 'many', 'a', 'woe', 'beside', ';', 'For', 'all', 'the', 'rulers', 'of', 'the', 'neighbour', 'isles', ',', 'Samos', ',', 'Dulichium', ',', 'and', 'the', "forest-crown'd", 'Zacynthus', ',', 'others', 'also', ',', 'rulers', 'here', '310', 'In', 'craggy', 'Ithaca', ',', 'my', 'mother', 'seek', 'In', 'marriage', ',', 'and', 'my', 'household', 'stores', 'consume', '.', 'But', 'neither', 'she', 'those', 'nuptial', 'rites', 'abhorr', "'d", ',', 'Refuses', 'absolute', ',', 'nor', 'yet', 'consents', 'To', 'end', 'them', ';', 'they', 'my', 'patrimony', 'waste', 'Meantime', ',', 'and', 'will', 'not', 'long', 'spare', 'even', 'me', '.', 'To', 'whom', ',', 'with', 'deep', 'commiseration', 'pang', "'d", ',', 'Pallas', 'replied', '.', 'Alas', '!', 'great', 'need']
Chapter 3 of the book on NLTK contains more information on how to deal with texts saved in other formats, such as HTML documents. For interested readers this can be found by following the link http://www.nltk.org/book/ch03.html.
In-class exercises:¶
1. Make a program that imports the text file “melville-moby_dick.txt” from the NLTK-library, uses the word-function to split the text into words and signs, removes all signs by making use of the function isalpha, and counts both the number of word tokens and the number of unique words that this file contains.
2. Use the word_tokenize-function of the NLTK-library to organize the file “mitthjerte.txt” as a list of words and signs. Print the length of the list and the list to screen. Further use the functions split and isalpha to organize the same text into a list of word tokens, and print the list and its length to screen. Now use the function set to make a list of words containing all unique words in the text file, and print the list and its length to screen. Do you see any difference between the lists and their lengths?
Examples on Natural Language Analysis¶
Having obtained a fair set of computational tools we are now ready to investigate the field of natural language analysis. In the following we will study the US Presidential Inaugural Addresses in the NLTK-Library to illustrate some of the available methods for categorizing a text’s complexity, finding the distribution of words in a text and observing how a given language evolves over time.
We start off by importing the set of US presidential speeches given in the period between 1789 and 2017. This set of text is saved in the corpus of NLTK under the name inaugural. Below we show how to import the US Presidential Inaugural Addresses corpus, and print the names of each text in the corpus to screen.
from nltk.corpus import inaugural
content = inaugural.fileids()
print(content)
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', '1801-Jefferson.txt', '1805-Jefferson.txt', '1809-Madison.txt', '1813-Madison.txt', '1817-Monroe.txt', '1821-Monroe.txt', '1825-Adams.txt', '1829-Jackson.txt', '1833-Jackson.txt', '1837-VanBuren.txt', '1841-Harrison.txt', '1845-Polk.txt', '1849-Taylor.txt', '1853-Pierce.txt', '1857-Buchanan.txt', '1861-Lincoln.txt', '1865-Lincoln.txt', '1869-Grant.txt', '1873-Grant.txt', '1877-Hayes.txt', '1881-Garfield.txt', '1885-Cleveland.txt', '1889-Harrison.txt', '1893-Cleveland.txt', '1897-McKinley.txt', '1901-McKinley.txt', '1905-Roosevelt.txt', '1909-Taft.txt', '1913-Wilson.txt', '1917-Wilson.txt', '1921-Harding.txt', '1925-Coolidge.txt', '1929-Hoover.txt', '1933-Roosevelt.txt', '1937-Roosevelt.txt', '1941-Roosevelt.txt', '1945-Roosevelt.txt', '1949-Truman.txt', '1953-Eisenhower.txt', '1957-Eisenhower.txt', '1961-Kennedy.txt', '1965-Johnson.txt', '1969-Nixon.txt', '1973-Nixon.txt', '1977-Carter.txt', '1981-Reagan.txt', '1985-Reagan.txt', '1989-Bush.txt', '1993-Clinton.txt', '1997-Clinton.txt', '2001-Bush.txt', '2005-Bush.txt', '2009-Obama.txt', '2013-Obama.txt', '2017-Trump.txt']
Lexical Diversity: Complexity of a Text¶
Reading an academic text versus a text in a magazine typically offers a different experience for the reader. Most likely the reader will find the academic text more impenetrable than the text in the magazine. What is it that makes one text more difficult to read than another?
To get an idea of the complexity of a text, there are a few tools that can be used, such as measuring the average word length, average sentence length and the lexical diversity score of a text. The lexical diversity score of a text refers to the ratio of the number of distinct word types (the size of the vocabulary) to the total number of word tokens in the text. In other words, it gives us the fraction of distinct words to the total number of words in the text. In the following we will show how to calculate such complexity measures for the presidential address given by George Washington in 1789, and the one given by Barack Obama in 2013.
First we save the filenames of the textfiles that we want to study as two new variables,
washington_1789 = content[0]
obama_2013 = content[-2]
print(washington_1789, obama_2013)
1789-Washington.txt 2013-Obama.txt
Average Word Length¶
The average length of words in a given text can be found by dividing the total number of words in the text by the total number of characters in the same text. Using the NLTK-functions raw to read the content of a given text, word to split the text into words and the Python-function isalpha to remove all numbers and puntuations, the average word length can be found by defining the following function,
def avg_word_len(corpus, fileid):
num_char = len(corpus.raw(fileid)) #Total number of characters in text
num_words = len(list(word for word in corpus.words(fileid) if word.isalpha())) #Total number of words in text
avg_word_len = num_char/num_words #Average number of characters per word
return avg_word_len
Running the function avg_word_length for the textfiles “1789-Washington.txt” and “2013-Obama.txt”, we get that
for fileid in [washington_1789, obama_2013]:
awl = avg_word_len(inaugural, fileid)
print(f"Average number of characters per word in {fileid[5:-4]}'s speech from {fileid[:4]} : {awl:.1f}")
Average number of characters per word in Washington's speech from 1789 : 6.0
Average number of characters per word in Obama's speech from 2013 : 5.6
From this simple analysis we can conclude that in his presidential address, Obama used on average shorter words than Washington, but the difference is not strikingly large.
Note that all file-ID’s in the inaugural corpus are saved as “year-president.txt”. Thus the first four characters of the name of each text file in this corpus make up the year the speech was held, and the four last characters gives the type of file that the speech is saved as (“.txt”-file). Thus the last name of the president who gave the speech is made up of all the remaining characters.
Average Sentence Length¶
Using the NLTK-function sents, we will now procede with a similar approach to the one above to find the average length of each sentence in the same two presidential speeches. The average sentence length can be found by taking the fraction of words in the text to sentences. This is shown in the code below.
def avg_sent_len(corpus, fileid):
num_words = len(list(word for word in corpus.words(fileid) if word.isalpha())) #Total number of words in text
num_sents = len(corpus.sents(fileid)) #Total number of sentences in text
avg_sent_len = num_words/num_sents #Average number of words per sentence
return avg_sent_len
for fileid in [washington_1789, obama_2013]:
asl = avg_sent_len(inaugural, fileid)
print(f"Average number of words per sentence in {fileid[5:-4]}'s speech from {fileid[:4]} : {asl:.1f}")
Average number of words per sentence in Washington's speech from 1789 : 59.6
Average number of words per sentence in Obama's speech from 2013 : 23.0
We observe that George Washington, on average, used longer sentences in his presidential address of 1789 than Obama did in his address in 2013.
Lexical Diversity Score¶
Finding the lexical diversity score of a text involves finding the number of distinct words, i.e. the number of vocabulary items, and divide this by the total number of words used in the text. How to do this is shown below. The lexical diversity score is between 0 and 1, and a higher score signals a higher diversity: in the limit, a lexical diversity score of 1 means that each word is used only once (the vocabulary size is the same as the number of words); a lower score means that words tend to be repeated.
def lex_div_score(corpus, fileid):
num_words = len(list(word for word in corpus.words(fileid) if word.isalpha())) #Total number of words in text
num_vocab = len(set(word.lower() for word in corpus.words(fileid) if word.isalpha())) #Total number of vocabulary items
avg_vocab = num_vocab/num_words
return avg_vocab
for fileid in [washington_1789, obama_2013]:
lds = lex_div_score(inaugural, fileid)
print(f"The lexical diversity score of {fileid[5:-4]}'s speech from {fileid[:4]} : {lds:.2f}")
The lexical diversity score of Washington's speech from 1789 : 0.41
The lexical diversity score of Obama's speech from 2013 : 0.37
Note that writing
words = [w.lower() for w in corpus.words(fileid)]
is the same as writing
words = []
for w in corpus.words(fileid):
words.append(w.lower())
In-class exercises:¶
* Make a function “lexical_complexity” that takes the name of a corpus and a file-ID as input arguments, and returns the average word length, average sentence length and the lexical diversity score of the text. Use the function to compare these measures for Obama’s speech in 2013 and Trump’s speech in 2017, found in the inaugural corpus of NLTK. Do you see any interesting differences?
Frequency Distributions¶
It is often practical to make a frequency distribution for some given parameters when doing language analysis. In general terms, this means to study how often a given parameter occurs as a function of some other parameter.
For language analysis a particularly useful structure to study is the frequency distribution of a set of words as a function of a given parameter.
In the following example we study the frequency distribution of words as a function of their length.
def freq_dist(corpus, fileid):
words = corpus.words(fileid)
N = len(words)
"""Making a list containing the length of words"""
len_words = []
for w in words:
len_words.append(len(w)) #Making a list containing the length of all words in the text
"""Making a dictionary with length of word as key and frequency of occurrence as item:"""
w_dict = {x: 100*len_words.count(x)/N for x in len_words}
"""Sorting the dictionary elements in a list of tuples such that the shortest words come first:"""
w_sorted = sorted(w_dict.items())
return w_sorted
This function takes a corpus and a file-ID as input, and returns a list of tuples that is sorted such that the tuples containing the shortest words come first. The tuples are arranged so that the first argument is the length of the words and the second argument is the frequency of words with the given length.
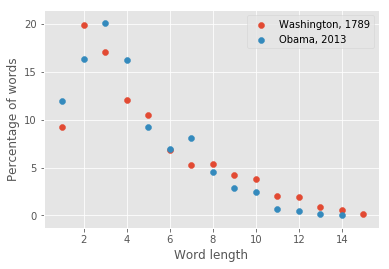
Plotting the fraction of words as a function of their length for Washington’s speech from 1789 and Obama’s speech from 2013 yields
import matplotlib.pyplot as plt
plt.style.use("ggplot")
for fileid in [washington_1789, obama_2013]:
len_word = []
freq_dist_word = []
fd = freq_dist(inaugural, fileid)
for i, j in fd:
len_word.append(i)
freq_dist_word.append(j)
plt.scatter(len_word, freq_dist_word, label=f"{fileid[5:-4]}, {fileid[:4]}")
plt.ylabel("Percentage of words")
plt.xlabel("Word length")
plt.legend(loc="best")
plt.show()
Side note:
In the function freq_dist above the Python built-in function count is used. This function takes a value as input and returns the number of times that this value occurs in the given dictionary or list. If “numbers” is the name of a given list, and we want to find out how many times the number “4” occurs in this list, we write the following,
numbers = [4, 2, 3, 4, 5, 4]
occurence = numbers.count(4)
print(f"The number 4 occurs {occurence} times in the list 'numbers'.")
The number 4 occurs 3 times in the list 'numbers'.
Additionally the function sorted takes a list of tuples as argument and returns a sorted list of tuples. The returned list is sorted in increasing order. To make the dictionary into a tuple with keys as first element and values as second element of each tuple, the functionitems is used. In this example we thus get a returned list of tuples where the first element of each tuple is the length of the word, and the second element is the fraction of times elements of this length occurs.
Evolution of a Language¶
The corpus with the US Presidential Inaugural Addresses is useful to get a rough picture of the evolution of the American-English language during the past two centuries. Specifically, since these are presidential addresses, it is also possible to get a feeling of the political development in the US over the same time span.
One way to study the evolution of a language is to make use of the complexity measures introduced above. We indicated in the examples above that both word length and sentence length may have decreased in the American-English language o over the past two centuries. However, there may also be other factors affecting this result, such as individual differences between the respective presidents in their way of speaking, and for example knowledge about rhetorics. For such a small data set it is thus difficult to draw any rigorous conclusions, and all we can hope to acheive from these analsysis is an indication to how the language may have evolved.
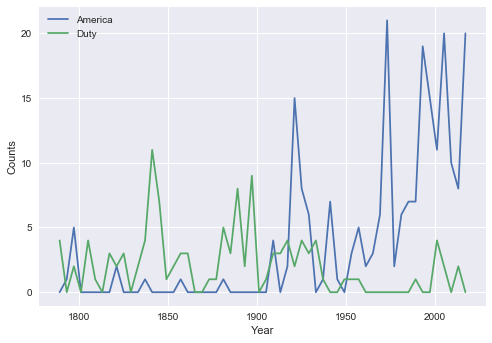
Another way of getting a qualitative understanding of the evolution of the American-English language and politics during the past 200 years is to track the occurrence of different words used in the presidential speeches over time. In the example below we track the occurrence of the words “america” and “liberty” in the US Presidential Inaugural Addresses as a function of time.
def word_count(corpus, fileid, word):
count = 0
words = corpus.words(fileid)
for w in words:
if w.lower() == word:
count += 1 #Counting each time the given word occurs in the text
return count
The function above takes a corpus, a file-ID and a given word as input, and returns the number of times the given word appears in the text. In the code below this function is used on the specified words in the presidential addresses, and the number of times the words occur are plotted as a function of time.
from nltk.corpus import inaugural
import matplotlib.pyplot as plt
fileids = inaugural.fileids()
words = ["america", "liberty"]
"""For each word, make a plot of the number of times the given word occurs as a function of year:"""
plt.style.use("seaborn") #This line makes the plot look fancy. Can be neglected.
for word in words:
count = []
year = []
for fileid in fileids:
year.append(int(fileid[:4])) #List of years. The year is given as the four first characters of the filename.
count.append(word_count(inaugural, fileid, word)) #List with number of times given word occurs
plt.plot(year, count, label=word.title())
plt.legend(loc="best")
plt.xlabel("Year")
plt.ylabel("Counts")
plt.show()
In-class exercises:¶
* Use the code above to study the evolution of the words “citizen”, “freedom”, “democracy”, “constitution”, “honor”, “duties” and “slavery” in the US Presidential Inaugural Addresses. What do you see?
Modify the code to plot lexical diversity scores in the US Presidential Inaugural Addresses